


Longer Thoughts - The effects of faster LLM inference
Last week, OpenAI released the model that powers ChatGPT — its 10x cheaper and ~5x faster than GPT3.5. What does that mean for the future?

Last week, OpenAI released the model that powers ChatGPT via a new text completion endpoint called gpt-3.5-turbo. Headlining that announcement: the new API is 10x cheaper (and anecdotally ~5–10x faster) than previous text completion APIs, while being similarly capable.

The announcement has many ramifications, but the first is obvious: the cost of developing with OpenAI just dropped 90% (assuming you can use the new API). This is game-changing for a lot of companies that were facing tight margins on the old APIs.
I think two other consequences are potentially even more impactful:
Applications that were not previously feasible are now (mostly due to latency constraints, sometimes due to costs).
We can start to speculate about future performance improvements and what those could enable.
In this blog, I’ll dive into the large language model (LLM) applications that are now feasible (that weren’t before) and speculate about what applications might become feasible as inference cost continues to improve.
What did the ChatGPT API change?
When building any software, it’s natural to consider the time budgets associated with various actions. Here’s roughly how I think about it:
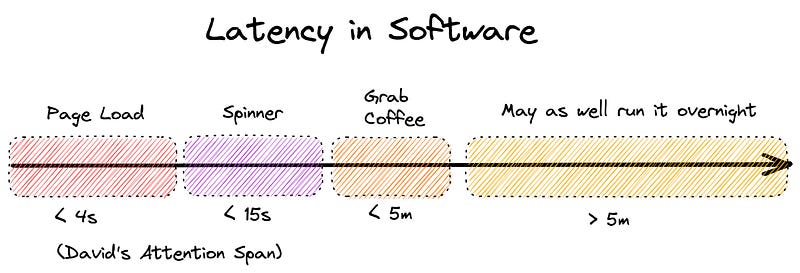
Each one of these gaps has an incredibly noticeable jump in how productive your users can be. In 2006, Google found that a 500ms increase in latency caused a 20% decrease in traffic and revenue. Once you get past a few seconds, you are almost guaranteed to lose someone’s attention to other work (or maybe TikTok). After a few minutes, you almost guarantee your user has moved on to something else and will return to your product “eventually.” These razor edges really matter!
There is a very similar story for the developer velocity of your product:

Maintaining focus while iterating and debugging software is critical to development velocity. From someone who has spent large periods of time building ML models that have multiple-day development cycles, it’s incredibly hard to innovate effectively when iterating that slowly.
Let’s fit GPT-3.5 (text-davinci-003 in OpenAI speak) into this diagram:

For customers: Tough start! We can’t easily fit a call to a model in a page load. One call to text-davinci-003 often costs at least a handful of seconds. That means doing essentially anything interesting risks losing user attention — there are a lot of loading pages in most LLM apps to date!
For developers: In the scheme of things, it’s pretty easy to iterate on a single prompt with davinci — waiting a few seconds to debug isn’t too bad. Things get ugly once you try to build something complicated, though. Testing long chains of inference starts to take a lot of time, making iteration painfully slow.
This is where the new API makes a huge difference:

For customers: One call to the new chat API can fit in a reasonable page load — that means you can feasibly customize a page on load for a customer. Pretty sweet! Also, now you can fit chains of calls into a reasonable spinner — a lot of the cool demos built with langchain or llama-index can now fit into great user experiences.
For developers: Developing chains is way more bearable with faster models, meaning it will be way faster to iterate on the development of more complicated LLM applications. Good developer velocity is insanely important for the pace of innovation.
In short: there is a whole new category of applications that have become feasible! Chains of LLM calls enable incredible experiences — LLMs with enough time can do multi-step reasoning, call out to APIs, and act like agents. The fact that those applications can fit into a human attention span will make a huge difference in their adoption.
Looking forward — what happens when we get 10x faster again?
There isn’t much reason to believe that we can’t continue to drive down the inference cost of similarly performant models even further. LLaMA from Facebook performs better than base GPT-3 on a more than 10x smaller model. Many teams are working on improving hardware utilization and making specific optimizations for inference. Fine-tuning is a promising approach to improve the performance of smaller models. There are fundamental limits that we’re approaching in chip design, but I have no reason to believe we’re particularly close to lower bounds of inference performance today.
So what could we do with a 10x faster model than Chat?

Here are a few examples of what this looks like on the interactive end of the spectrum:
Simple chains in a page load: This is likely pretty revolutionary — chains enable all sorts of capabilities. Research like Toolformer tells us that we could use LLMs to make calls out to external systems and perform work. LLMs can do multi-step reasoning over knowledge bases — this could power more significant per-user customization of every product.
Process large documents in a loading screen: For example, you could summarize large amounts of research or the full results of a google search (including page contents) while waiting for a progress bar to finish.
The possibility space is much larger than these examples; a ton of innovation will happen as more calls to language models can be crammed into reasonable amounts of user time.
Conclusion
Timelines are hard to predict in AI, and many of the development cycles at the cutting edge seem more focused on improving the “accuracy” of models (building GPT-4/5/…) rather than improving the inference speed of similarly capable models. That said, this blog is meant to illustrate that there are interesting product possibilities that emerge with both improvements:
When the model gets more capable, new use cases become possible
When the model gets faster, new use cases become feasible
My key takeaway: we’re in the (very) early days of what is possible with LLMs. There are so many angles to innovate, and each one opens new possibilities. As progress gets made on improving LLM inference speed, I expect more complicated architectures that process more information to become mainstream. Buckle up: we’re in for some fun innovations in the next few months.
David Hershey is an investor at Unusual Ventures, where he invests in machine learning and data infrastructure. David started his career at Ford Motor Company, where he started their ML infrastructure team. Recently, he worked at Tecton and Determined AI, helping MLOps teams adopt those technologies. If you’re building a data or ML infrastructure company, reach out to David on LinkedIn.