
Llama 2: Time to Fine Tune
The Llama 2 annoucement, and what it means 7/20/2023

The Facts
Meta AI released Llama 2 yesterday, and it looks like the largest model in the class (Llama 2 - 70B) is roughly as capable as GPT-3.5:

They open-sourced the model and weights with a sufficiently permissive license that most teams can use the weights commercially (they have a provision that blocks applications with 700M+ active users from using the model).
So far, the evaluation scores seem to pass the smell test — folks who have been testing Llama 2 seem to think that the model really is roughly as capable as GPT-3.5 on most tasks (except code generation).
Why it matters
Let’s revisit the chart I put together for Claude’s release:
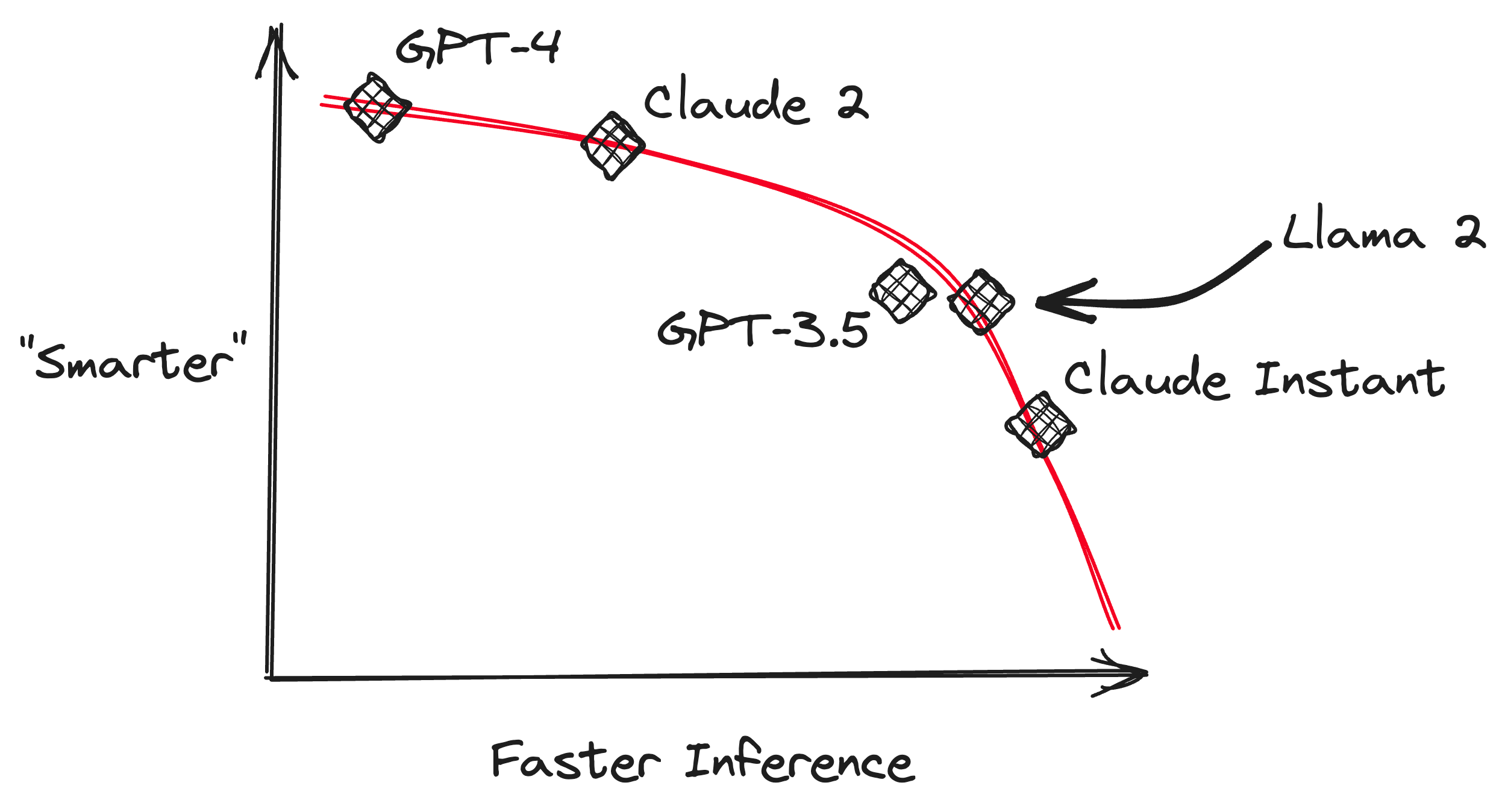
At face value, another model of roughly the same quality as GPT-3.5 isn’t that impactful, but when you layer in fine-tuning, things get pretty interesting:

We’re likely going to see some fine-tuned Llama derivatives comparable with GPT-4 on some specific tasks while being significantly faster and cheaper.
Why will fine-tuning take off right now? Without great base models, fine-tuning was simply not that effective. If fine-tuning only resulted in an “about as good” model as GPT-3.5 without tuning, there was very little reason to fine-tune.
Further, open-source models are fundamentally better fine-tuning targets than closed models. With an open model, you can choose a fine-tuning algorithm (SFT, QLoRA, even RLHF) and have much more flexibility to find the ideal tune for your use case.
My thoughts
What I think will define the next year in LLMs:
I don’t think a model more capable than GPT-4 will come out in the next 12 months
Fine-tuning tooling is improving quickly, with methods like QLoRA and platforms like Lamini
Llama 2 is the first very compelling open-source base model for fine-tuning
I expect us to enter the fine-tuning era in the next few months