
6 Ways to Choose a Language Model
Choose your own adventures, LLM style -- 7/18/2023

The Facts Some helpful diagrams
A topic that keeps coming up in the LLM industry: a lot of enterprises are uncomfortable with relying on closed-source, hosted LLMs (like those provided by OpenAI). I put together a handful of references to lay out your various options as a developer when selecting a language model and wanted to share them here (with light commentary):

Using a model endpoint provided by one of the large model providers is the most common way language models are used today. OpenAI has a significant lead, but others are catching up.
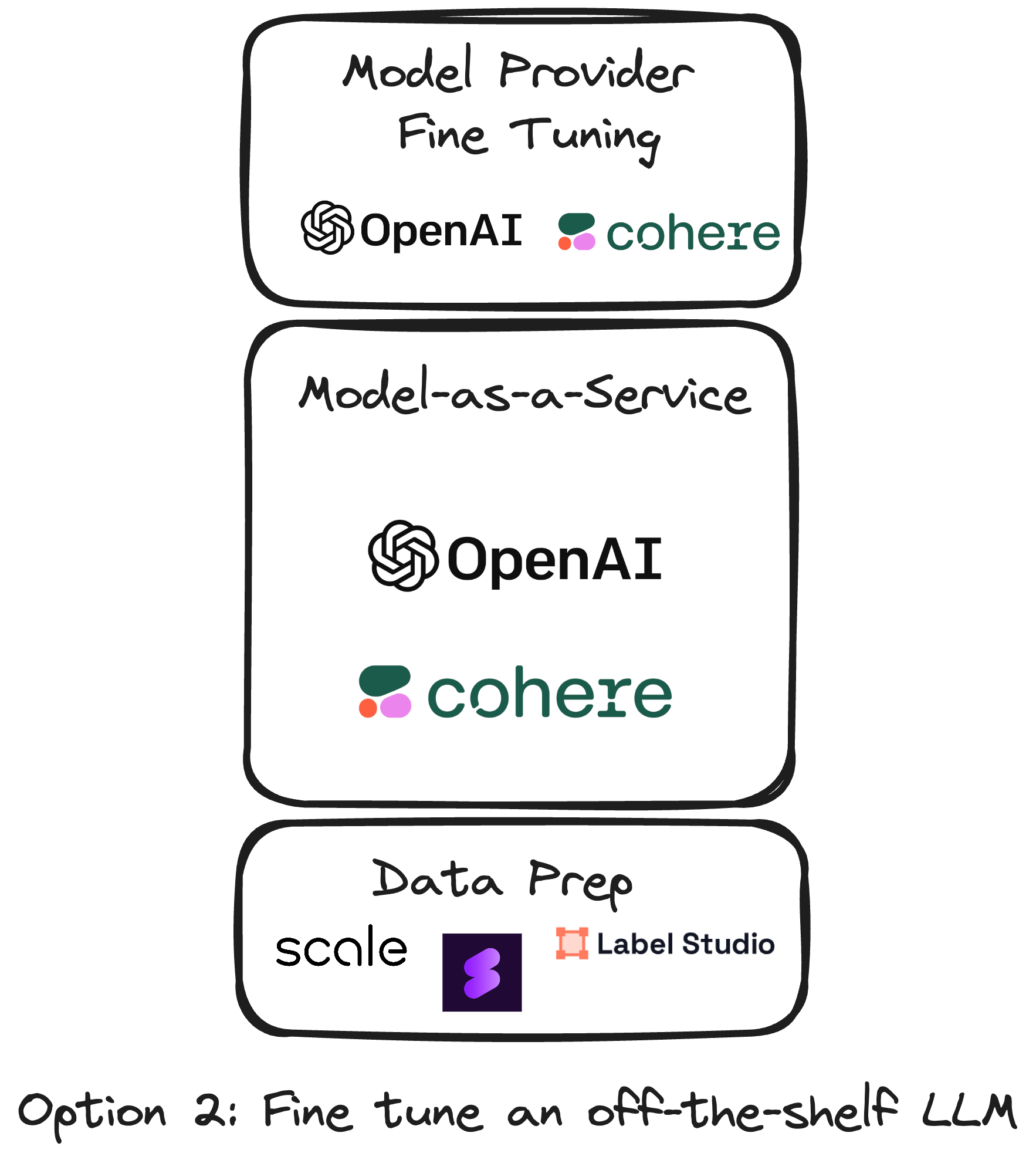
About 8 months ago, fine-tuning models using the OpenAI fine-tuning endpoint was also a popular method — this has fallen out of favor since OpenAI does not yet support fine-tuning for GPT-4. They have said this capability is coming later this year, I expect this option to become more popular then.
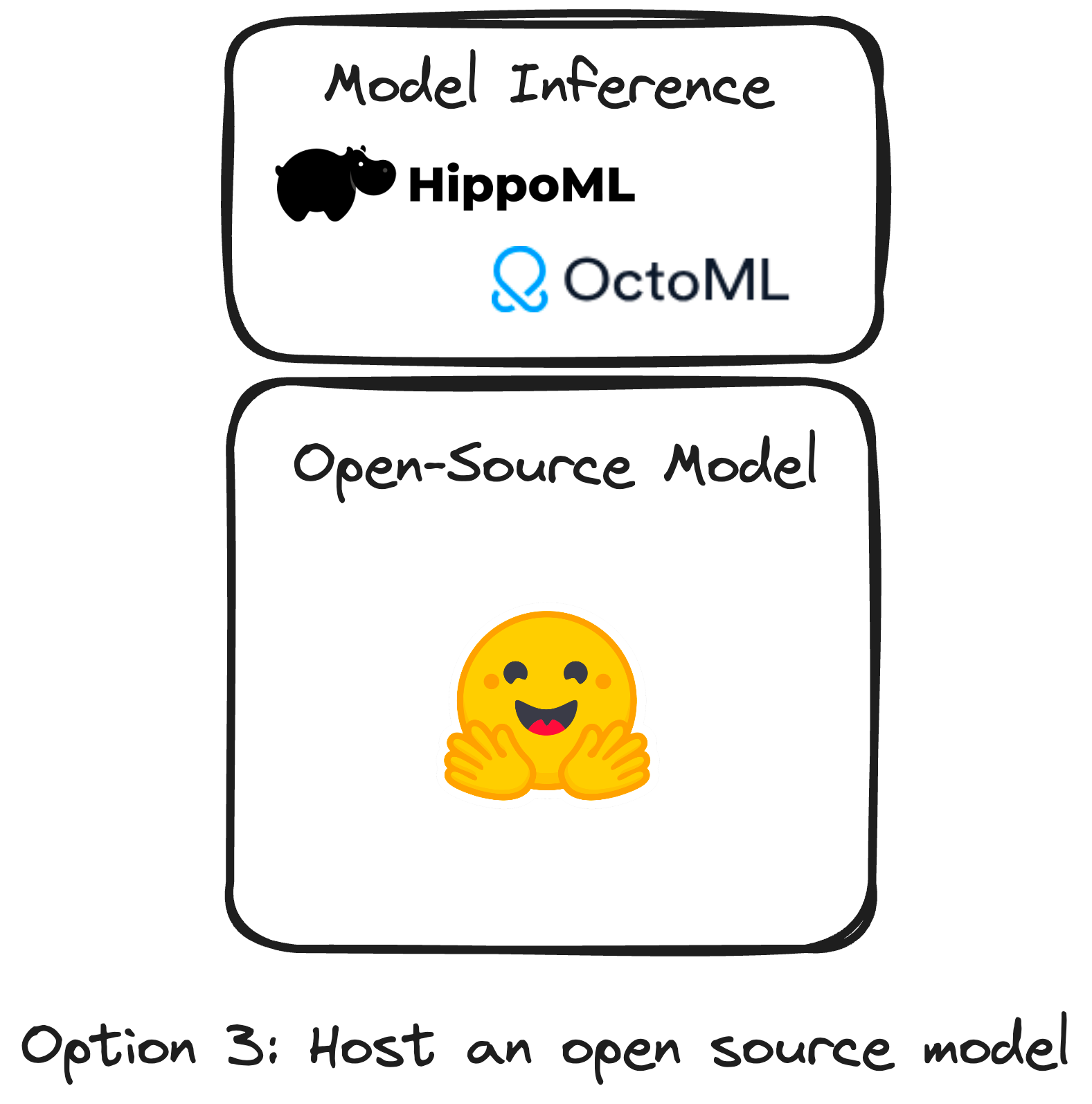
There are a lot of open-source LLMs out there! With LLaMA 2 releasing today, we finally have an OSS model almost as capable as GPT-3.5, its worth trying out!

To help close the performance gap, you can fine-tune an open-source model for your specific task. There are a few approaches out there for fine-tuning — for example, Lamini just released their hosted fine-tuning offering.

Alternatively, you can fine-tune a model yourself! This looks a lot like classic ML model training and will probably involve a good chunk of GPUs — you’ll probably end up using a GPU cloud like Together or Lambda.

For the bold, you can pre-train your own language model. I don’t recommend this for most people (the pretrained base models are so powerful!), but there are some famous examples like BloombergGPT.
That’s all for today — let me know if I missed anything (or if you’re one of the teams training your own model, that’s always interesting!)
What an informative piece! It's great to have a clear overview of language model options and their evolution. Kudos to David for breaking down the choices so effectively!
If you're serving inference at scale, your best option is salad.com :)